Transformers are the essential parts of deep neural network, and widely used in Natural language processing tasks. We have a wide variety of usages where transformers are used in real time scenarios, such as, translations, text generation, question answering and various other NLP tasks. One of the widely used examples of transformer is Chat GPT. More information about transformer architecture and its mechanism can be accessed on page Understanding Transformers (BERT & GPT).
One of the very important processes in transformers is Finetuning. Finetuning is the way for adapting the OOB (out of the box) model for your specific tasks. In other words, it is the process of training a pre-trained model on your specific datasets to adapt the knowledge from new dataset. During fine-tuning, the parameters of the pre-trained model are adjusted based on the task-specific dataset. The goal is to adapt the model’s knowledge to perform well on the particular task of interest.
Let’s understand how finetuning works. Below is the example of finetuning a pretrained BERT transformer from Hugging Face library on Squad dataset. Squad dataset is a prebuilt opensource question answering dataset published by Stanford University, and widely used for experimenting and training on NLP based deep learning models.
Loading and importing modules
You have to load modules such as transformers, dataset for finetuning transformers. This example has used TensorFlow, so install TensorFlow also if not done already.
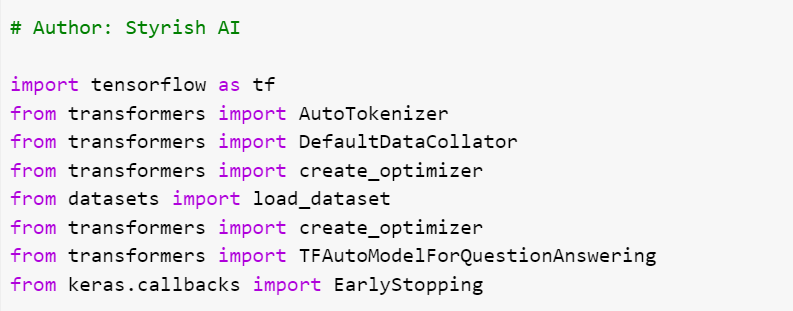
Loading Dataset
Squad is really a very huge dataset and more than enough to train your NLP model. I have used only 4000 entries from that dataset for demonstrating purposes. If you notice, I have also loaded the pretrained BERT tokenizer from the Hugging face library in the same cell, which we will use to tokenize the squad data compatible with BERT. Different models have different tokenizers in the library, and you should be loading the correct tokenizer compatible to the model you are fine tuning. For example, BertTokenizer is for BERT model, GPTTokenizer is for GPT model etc. AutoTokenizer class is helpful to load the correct tokenizer for you based on the name of the model passed.
train_test_split operation has been invoked over the dataset to split it in 80/20 ratio. You can change the test size according to your need, but 20% of the entire data for validation is an ideal approach.

Squad contains the five fields in it, such as, Id, title, context, question and answer. Context, question and answer are important fields, which will be needed to train or finetune the model for question answering.

Preprocessing the Dataset
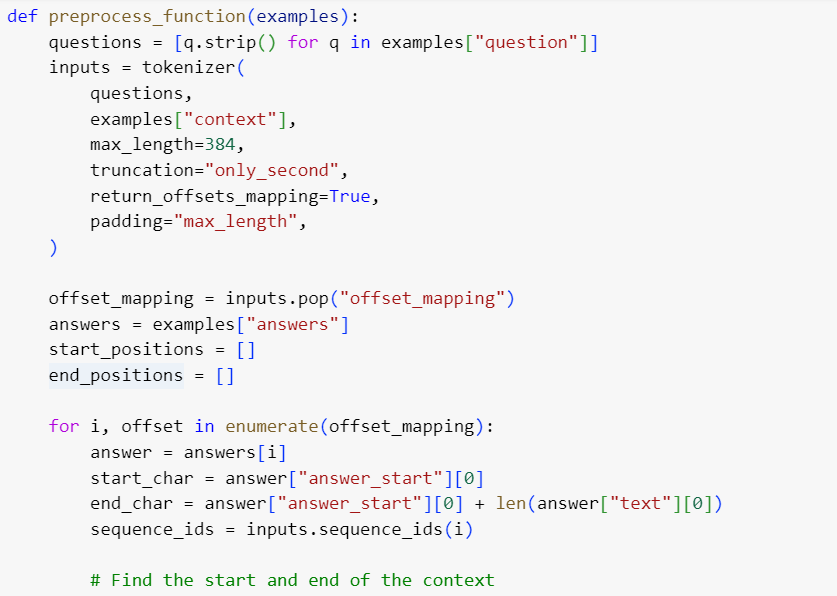
For Question answering tasks, you may have to preprocess your data. Below function will pre-process your data, that will include tokenization of data, truncation and padding of data, adding special tokens ([CLS], [SEP]) to the sequences, creating attention masks etc. The specific transformer tokenizer (in this case, BertTokenizer) will perform all these steps. To know more about tokenization, please refer to Data Preprocessing in NLPs section in Data Pre-processing with Datasets and Data Loaders page.
While truncating the data, you may need to be careful about texts which exceed the maximum input length of the model. To deal with longer sequences, truncate the context by setting truncation=’only_second’.
Map the start and end positions of the answer to the context by setting return_offset_mapping=True. Once the mapping is done, you can find the start and end tokens of the answer. Use the sequence_ids method to find which part of the offset corresponds to the question and which corresponds to the context.
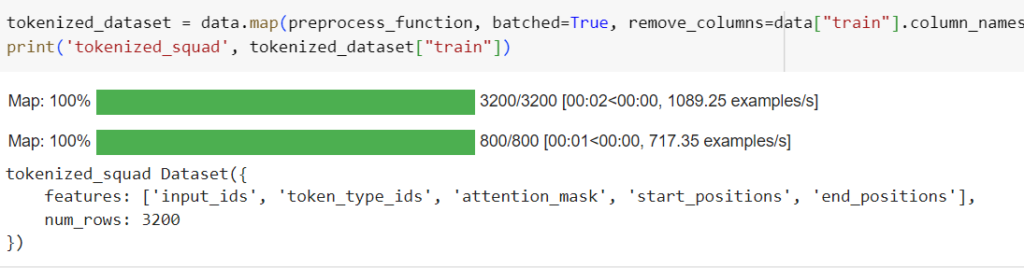
Below is the detailed preprocessing function, which you have to apply on the entire dataset.

Training the model
Next step is to train the model on above preprocessed dataset. While fine tuning transformer model, I have chosen one of the most popular pretrained BERT models, named ‘bert-base-uncased‘. Also, I have prepared the above dataset compatible to TensorFlow using prepare_tf_dataset in TensorFlow library. This will convert the dataset to TensorFlow compatible tensors.


Define the loss function and optimizer and train the model on training dataset for specified number of epochs. Here, I have chosen the number of epochs as 4 for demonstration purposes. If you see the below output, the is keep on decreasing on each epoch. This is our goal.
Model’s performance on matplot is given below.
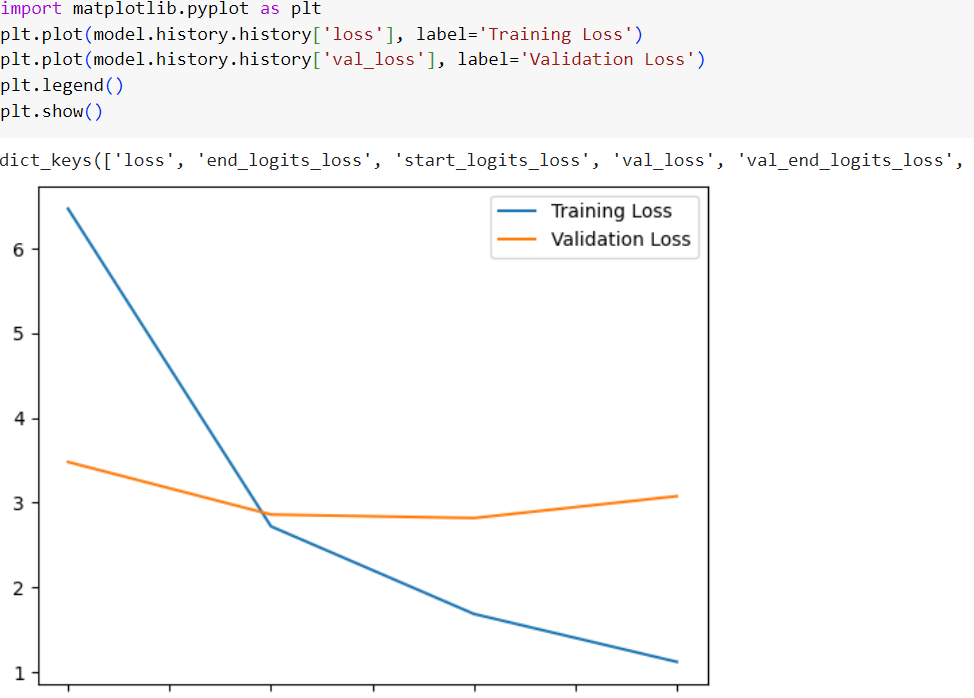
This is just for demonstration purposes and may not be the ideal performance of model. You may need to adjust the hyperparameters to get the optimum performance.
For more information about training and validation process, please refer to the page, Training and Validation Process of Model.
Here is the link to a question answering website. In this platform, we have employed a finetuned Longformer, an extended version of Transformer, specifically designed to handle longer sequences. While Transformer allows a maximum input sequence length of 512, Longformer overcomes this limitation, accommodating sequences of up to 4096 tokens.
https://apps.styrishai.com:8443/ncert/ai/qa
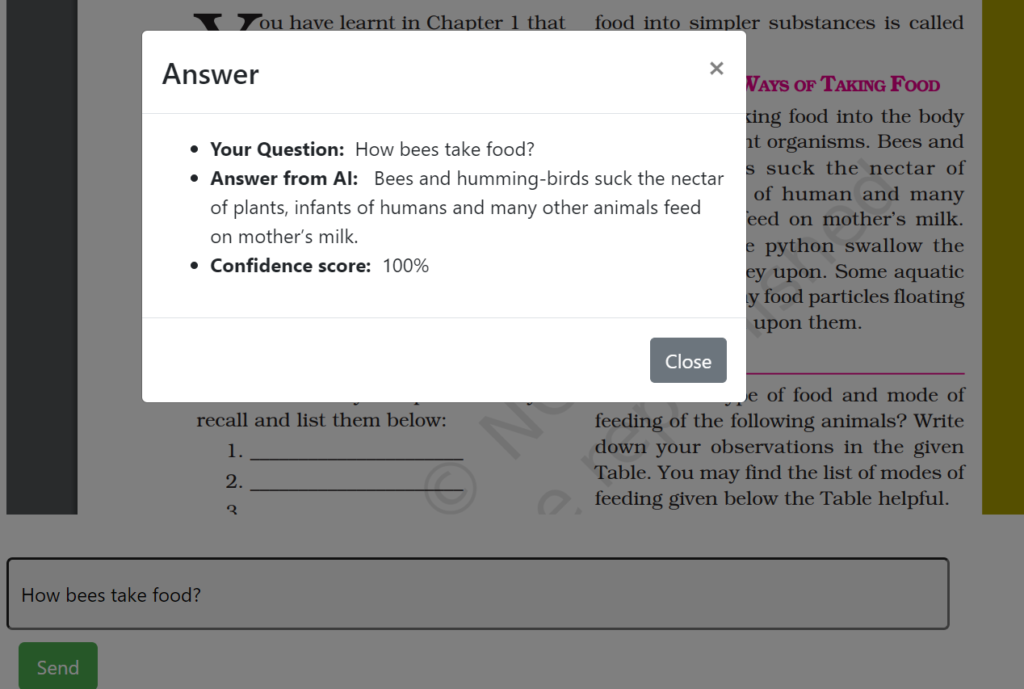

Above screenshots show how the answer for the input question is picked from the context provided. This Longformer has been fine-tuned on the NCERT dataset, which was collected and prepared by Styrish AI.