Convolutional Neural Network or CNN for short, is one of the widely used neural network architecture for image recognition. It’s use cases can be widely extended to various powerful tasks, such as, object detection within an image, image classification, facial recognition, gesture recognition etc. Indeed, Convolutional Neural Networks (CNNs) are designed with some level of resemblance to the image recognition process in the human brain. For instance, In the visual cortex, neurons have local receptive fields, meaning they respond to stimuli only in a specific region of the visual field, which is achieved by CNN using kernels or filters. Both human brain and CNN process the visual information in hierarchical manner. Basic information of an image is extracted via lower level of neurons in human brain, and higher-level neurons integrate the information from lower-level neurons to identify the complex patterns. On the other hand, in CNN, we use multiple convolutional layers to extract hierarchical features from the input. You can get more information about CNN architecture from one of our pages, What is Convolutional Neural Network (CNN)?
Going forward, there are many frameworks and libraries designed to develop neural networks applications, and can be used for CNN also. One of the widely used frameworks is TensorFlow, which was developed by Google, and released in 2015. Let’s demonstrate TensorFlow with one of the sample and simple CNN use cases. Consider a model which would distinguish between the images of animals and buildings. Classifying images of animals and buildings would be relatively simpler than classifying the different breeds of dogs. So, let’s take that example for a better understanding of CNN.
Preparation of dataset
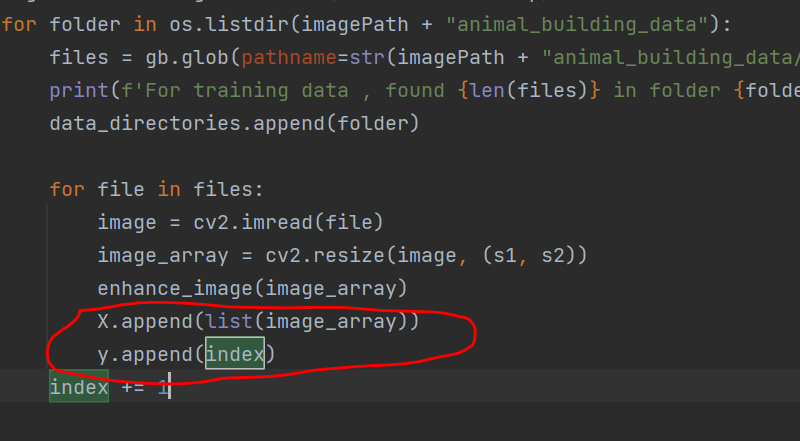
I have collected few images of animals and building and organized those at a certain location in my laptop. Better to keep images in folders labeled with class names, like, animal images in animal folder and building images in building folder. Let’s read those images and prepare our training and testing data. Image arrays will be stored in X and their corresponding label or class will be stored in Y.
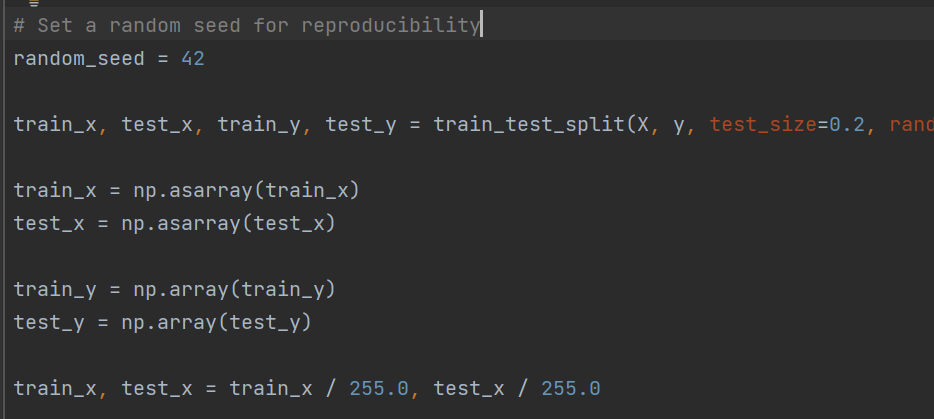
Now, we would be needing to split our data for training and validation purposes. Best practice is to split the data into 80/20 ratio, where 80% of the images will be used for training and 20% of those will be utilized for validation of the model (validation data is the unseen data to the model). Notice that I have normalized the images after dividing those by 255. Normalization is one of the standard processes for image processing. you can read it from our page, Data Pre-processing with Datasets and Data Loaders.
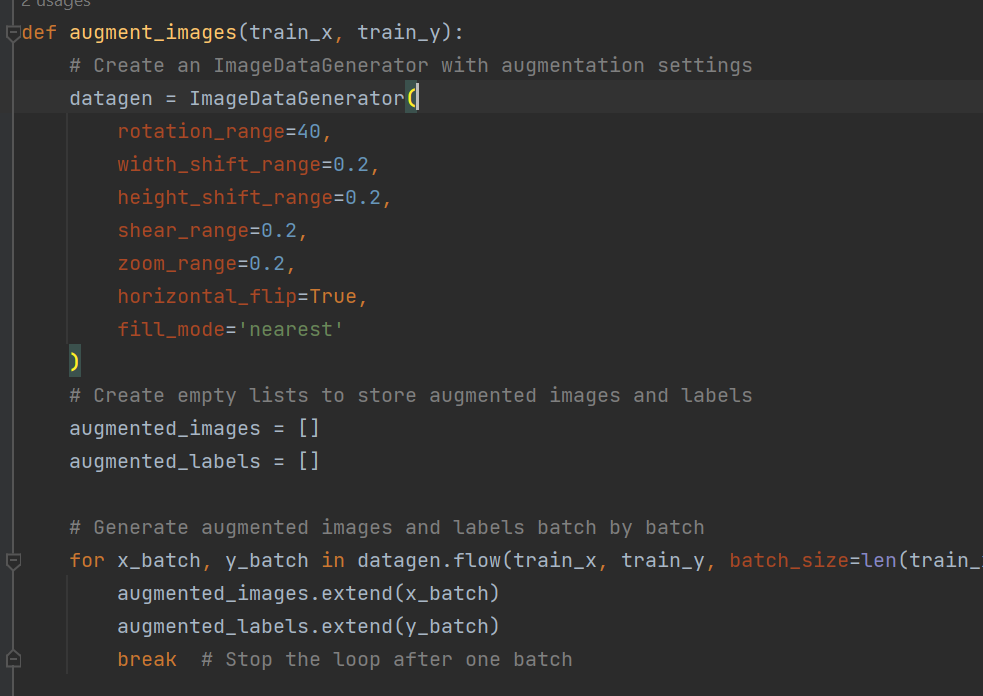
Another optional step is image augmentation, which is used to produce the diversified version of available images. It is a very useful technique when you have a small amount of data, and you can increase it using image augmentation. More information about image augmentation can be read from our page, Data Pre-processing with Datasets and Data Loaders. It has been explained on this page using PyTorch, but you can understand the concept and correlate it with TensorFlow.
Compiling and training of the model
It’s time to create a CNN model using various layering components in the library. For CNN models, we mainly use convolutional layers, pooling layers, flattening and dense layers. Each layer has its specific function. You would notice that I have opted for a couple of sets of convolutional and max pooling layers, along with a set of flatten and dense layers at the output. Conv2D parameters signifies the number of filters or kernels to be used, size of kernels, activation function (in this case ReLU), input shape of data (in this case 224x224x3), number of strides in both the dimension (height & width). For more details on each layer of CNN, and their parameters, please refer to the page, What is Convolutional Neural Network (CNN)?

Compiling the model
Furthermore, compile function in tensorflow-keras library has been used to configure the learning process of the model. This function specifies the optimizer, loss function, and evaluation metrics for the model. optimizer and loss functions are extremely crucial part of deep learning architecture. using the optimal values, our goal is to decrease the loss at each iteration or epoch. One of the prominent optimizing algorithms in deep learning architecture is ‘Gradient Descent’. For more information on optimizer and loss functions, please refer to the page, What are Optimizers and Loss Functions?
Training the model
Finally, it’s time to run the training. “fit” function in tensoflow-keras library has been used to run the training of the model. Parameters to this method are training data (in this case, train_x and train_y), epochs (no of iterations the model will go through the training data during the learning process), validation data (in this case, test_X and test_Y ), and callback objects (callback objects to perform certain actions at various points during the training process, such as, early stopping, TensorBoard logging to send metrics to TensorBoard for visualization and troubleshooting).

For more information on training and validation process of the model, please refer to the page, Training and Validation Process of Model. It has been explained here using PyTorch libraries, but you would be getting a detailed understanding of the concept.
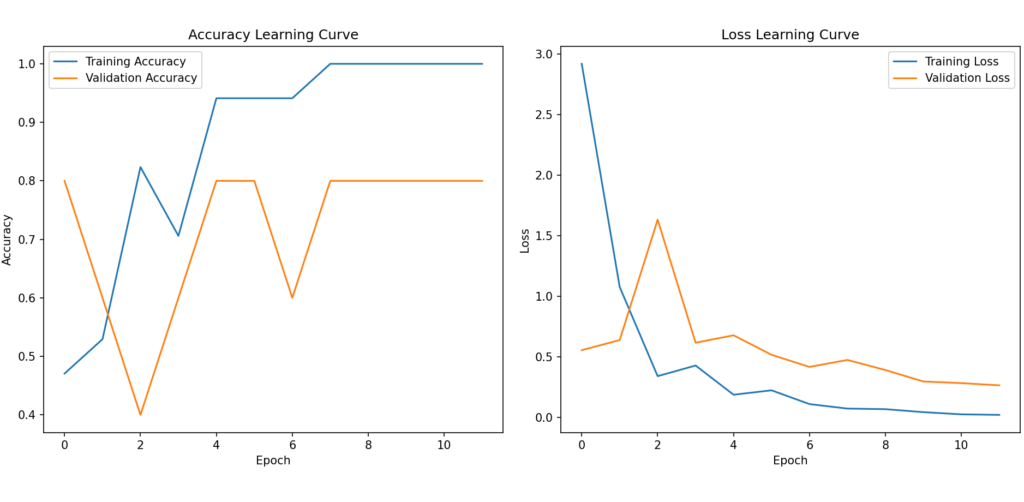
Below is the output of the program. It ended up the model with 80% accuracy on test data. We can save this model to any location, and case use it further for classifying the images of animals and buildings. It looks like, the graphs are little zigzag, those can be improved by incorporating more training data. Ideally, the accuracy should be increasing continuously, and loss should be decreasing in the same fashion. That’s it.!!

Pingback: Using TensorBoard with Machine Learning - styrishai.com