Convolutional Neural Networks or CNN for short, are the elements of Deep Neural Networks which are primarily used computer vision, image or video recognition, and image classification using neural network algorithms. An example of CNN is a model that recognizes the images between cats and dogs. This is an example and more complex uses cases in CNN are possible.
CNN converts input images to its corresponding pixel arrays, which is further processed through various layering network, that includes mainly convolutional layer, pooling layer and fully connected layers. After input array is processed through all these layers the final output is performed, or the image is classified.
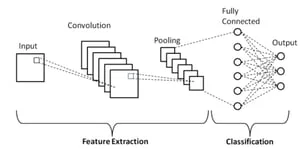
Let’s understand the flow in more detail.
Convolutional layer
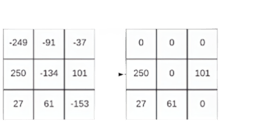
When the image is processed, the first layer comes on the way is convolutional layer or Conv2D, which applies kernels of various sizes (user defined) on input image to extract the main features of the image such as edges or some patters in input data like ears and eyes of cat or dog etc. Once the kernel or filter is applied on the image vector, feature map is extracted which is further passed to activation functions such as Rectified linear unit or ReLU (mostly used).
Activation function (ReLU)
ReLU function will introduce the non linearity in the input. In other words, activation function will help network to ignore less significant features which can be more overhead for model to recognize the image. ReLU function simply says, if the value in feature map is < 0 then convert it to 0, else the value i.e. f(x)=max(0,x).
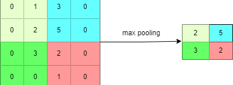
Pooling layer
Output of activation function is further passed to pooling layer, where the feature map is down sampled to make subsequent computations more efficient. There are various types of pooling can be applied on map, such as max pooling or average pooling etc. In max pooling, For each local region in the input map (e.g., a 2×2 or 3×3 window), the maximum value is selected as the output, and the average is selected in average pooling.
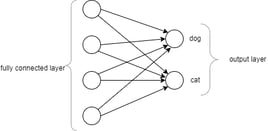
Fully Connected Layer
These layers are mostly at the last of the network, where all the neurons of this layer are connected to all the neurons of next layer. Next layer may be another fully connected layer or output layer. Feature map output from pooling layer is flattened to 1D vector before passing to fully connected layer. This can be understood as, suppose there are three feature map outputs from three max pooling layer. Each map is about the local feature of image. (example ear or eyes). These outputs will be further flattened and combined together before passing to fully connected layer to do the prediction for full face. Flattening of image vectors before passing it to fully connected layer is below.

Output Layer
This is the final layer of CNN network, which contains number of neurons equals to the number of classes being predicted. For example, If model is designed to predict between dogs and cats, output layer will be having two neurons, each will be representing to one class. Each neuron of fully connected layer is connected to each neuron of output layer. (each neuron for each class). Confidence score is calculated for each neuron in output layer. The neuron with the higher confidence score is considered the correct and the class is predicted. SoftMax function can be applied on scores to interpret the output as probabilities. The output of SoftMax function is within the range of 0 to 1. Closest value to 1 is most likely the answer.
For more understanding of code for CNN, please refer CNN LAB.