Transformers are the type of deep learning model architecture that poses a significant capability in handling NLP tasks. This made them broadly utilized in tasks like machine translation, text summarization, question answering, and language understanding. Pre-trained transformer models like BERT (Bidirectional Encoder Representations from Transformers) and GPT (Generative Pre-trained Transformer) have gained remarkable performance and have been used as the foundation for many downstream applications in natural language understanding.
The basic components of a transformer are encoder and decoder. The encoder processes the input sequence, while the decoder generates the output. Both the encoder and decoder consist of multiple layers of self-attention mechanisms and feedforward neural networks. Encoders and decoders can be used standalone or combined in models resulting in Encoder-Decoder models, which is also known as sequence-to-sequence models. (Below is the image of encoder-decoder).

Encoders
Encoders are one of the basic building blocks of Transformers. Encoders are used for processing the input sequence, which can be a set of words or tokens. An encoder processes the input sequences and converts them to its corresponding meaningful numerical representations, which is an array of numbers for a single word or token. These numerical representations are called feature vectors. Example of a feature vector for a sample text is below.
| Text | Example feature vector |
| ‘Transformer, tutorial, from, Styrish, AI’ | [.3, .23, .5], [.42, .22, .75], [.14, .33, .61], [.5, .21, .14], [.58, .77, .6] |
If you see above, each token is mapped to its corresponding feature vector. Feature vector for specific token is generated by transformers’ self-attention mechanism, which helps to compute attention scores for each token in sequence, in relation to all other words in the sentence (attention score can be different for same token in different sequence based on the context in sequence). These scores reflect the importance of each word when forming the representation of the token. In Encoders, self-attention mechanism assigns the attention score to a token based on both the sides around it within the context (left and right), to capture the importance of the token.
Thus, these models are often characterized as having bi-directional attention mechanism and are often called auto-encoding models. Models designed for NLP tasks like text classification, sentiment analysis etc. usually have encoders only, as these types of tasks require both the sides of sequence (left or right) to deduce its importance within the context. For example, “I am going for running.” and “Running is important to stay fit.“. Here, “Running” may have different importance in both the sequences, which can be decided by model while moving from both the sides of sequence. (right to left and left to right). One of the popular examples of encode models based on the transformer architecture is BERT (Bidirectional Encoder Representations from Transformers), which was developed by Google AI, and primarily used for text classification (sentiment analysis, spam detection etc.), question answering etc. type of NLP tasks. Let’s understand BERT.
BERT (Bi-directional Encoder Representations from Transformers)
BERT (Bidirectional Encoder Representations from Transformers) is a deep learning model based on transformers architecture, and majorly used for NLP tasks such as text classification, sentiment analysis, spam detection etc. We have already discussed above that BERT uses encoder-based model, which travels across sequence in both the directions to decide the importance of token in the input sequence. The algorithm does this task is called self-attention mechanism.
Pre-training of BERT
BERT has been trained on large amount of publicly available text data on internet. This process is called pre training. BERT’s pre-training includes masked text prediction task, where the word within the context has been masked to perform the prediction by BERT, as well as understanding the relationships between the sentences. BERT can be loaded from hugging face repo using nlp pipelines and is ready to use.
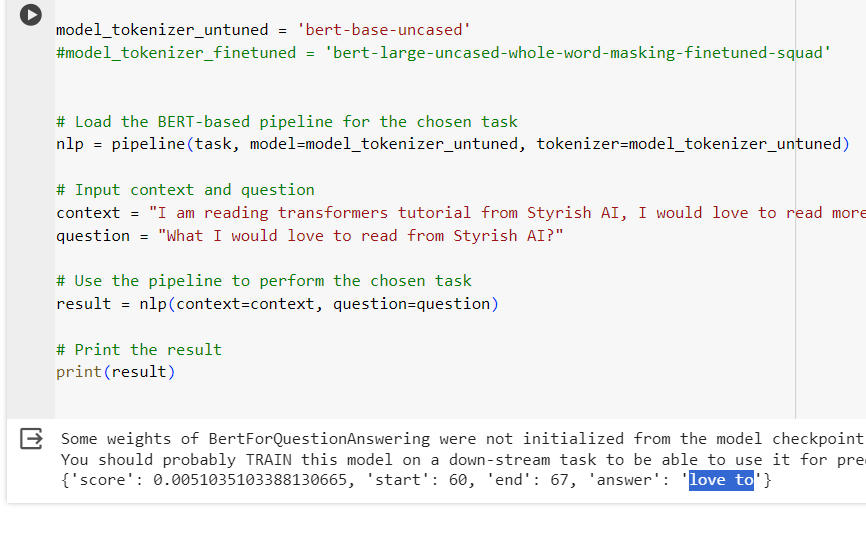
If you see in above screenshot, BERT is loaded from Hugging face nlp pipeline, and used for question-answering task. But here it seems, it is not giving pretty effective answer. For that, we need to finetune the pre-trained model on specific dataset.
Finetuning of BERT
Finetuning of BERT involves the similar steps as training any other deep learning model. Fine tuning means adapting the pre-trained transformer model on custom dataset. Any pre-trained transformer model can be loaded from Hugging face and further finetuned on a specific dataset (dataset may be specific to your organization or else). Finetuning process includes below steps.
- Load the pre-trained transformer model which is suitable for your task. Hugging face library provides various pre-trained BERT models available for further finetuning.
- Prepare the dataset specific to your requirement, on which the BERT model will be trained.
- Tokenize the data using BERT tokenizer. The similar tokenizer should be used on which the BERT is pretrained.
- Create the word embeddings from the tokenized data. This includes tokenIDs, segmentIDs and attention masks.
- Run the training of BERT on the prepared dataset. This process is a similar to other deep learning models, which includes calculate the loss, update the weights using back propagation and do the optimization.
- Run the validation on validation-dataset, make sure the loss is decreasing and accuracy is going high after each iteration or epoch.
- Once satisfied with validation results, save the model for future use.
BERT finetuning code is at the bottom of the page.
Decoder
Decoders are also the important building blocks of Transformers architecture. As their name suggests, they decode the feature vectors generated by encoders in sequence-to-sequence models such as T5, or as a standalone component in models such as GPT. They take a portion of input sequence and predict the next word in an auto-regressive fashion. Unlike encoders, decoders have the access to the left side (not both sides) of the token, or before the token to determine its attention score and predicting the next word in the sequence.
Decoders are auto-regressive
Decoders are auto regressive. They use their previous output as input to predict the next word. Decoders decodes the first embedded token from the sequence received from encoder, decodes it and send it to their (decoder) input to predict the next word. For simplicity, lets understand the process in steps.
- Decoder receives the embedded feature vectors from encoder. (For example, feature vector for sequence ‘This is Styrish AI’, as mentioned in encoder-decoder diagram above)
- It decodes the first token ‘This’.
- It sends the first token ‘This’ to its input and predict the next word ‘is’.
- It takes ‘is’ also as an input along with ‘This’ and predicts the next word ‘Styrish AI’.
This process keeps on going till the final result is achieved, hence auto regressive. In the decoder, the self-attention mechanism is often masked to ensure that during the generation of each token, the model only attends to the tokens that have been generated so far and not to future tokens (usually left side of the token). This is crucial for autoregressive generation, where the model generates one token at a time in a sequential manner.
Decoders are primarily used in text generation models if being used standalone. One of the examples of standalone decoder transformer is GPT (Generative Pre-trained Transformer). Decoder-Encoder Transformer model is also named as sequence-to-sequence model, which is mainly used for machine translation tasks. One of the examples of encoder-decoder model is T5 (already mentioned above).
GPT (Generative pre-trained transformer)
GPT or Generative pre-trained transformers are standalone decoder transformers, which are mostly used for NLP tasks related to text generation. The model consists of a stack of transformer decoder layers. During training, the model is pre-trained on a large amount of text to predict the next word or token in a sequence given the preceding context. The self-attention mechanism in the decoder allows the model to capture dependencies between different positions in the input sequence, enabling it to generate coherent and contextually relevant text. (It has already been explained above that how decoder works). Once trained, GPT can be used for a variety of downstream tasks without the need for a separate encoder, such as text completion, question-answering, text generation etc.
ChatGPT is an example of GPT transformers, which takes a sequence of data and outputs the answer. ChatGPT has been trained on extremely large amount of data so that it provides a precise answer for any question that is asked.
GPT transformer can also be loaded from Hugging face using nlp as we loaded BERT in above sections. Below is the screenshot of how GPT is loaded from hugging face and can be used for text-generation.
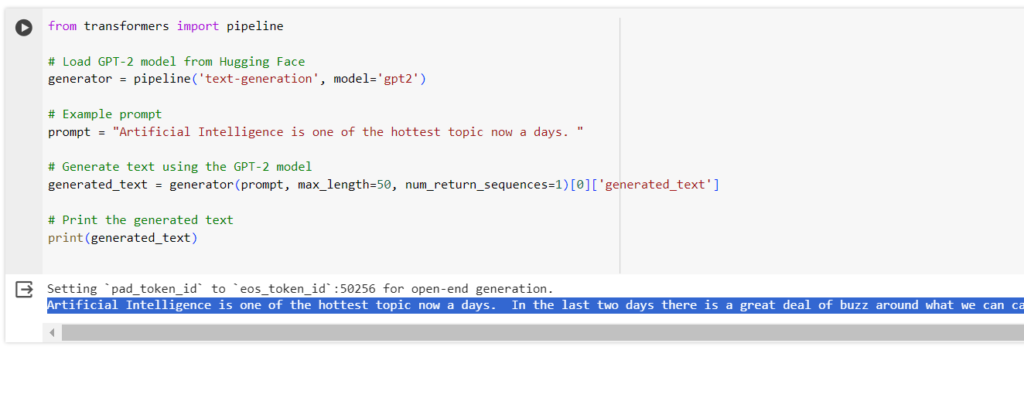
If you see above, how beautifully GPT has predicted later part of the input text. Alike other transformers such as BERT, GPT can also be finetuned on your specific dataset based on the need.