Training and validation are the key areas of deep learning. Training is the process of teaching a model to make predictions or decisions based on input data. During training, the model learns to map input features to output predictions by adjusting its weights through an optimization process. According to the procedure of training, model is fed with labeled training data, where both the input features and their corresponding correct outputs (labels) are known. For each iteration or epoch, model initializes the weights randomly at the start of training, predicts the output and compare it with provided ground truth or labels (sometimes referred as dependent variables), to calculate the accuracy and loss. Here, accuracy and loss can be considered as correct and incorrect predictions or interpretations respectively.
Validation on the other side, is the process for validating the model. Once the training has been completed, model is evaluated against the unknown or unseen data. You can correlate the scenario with a student having examination (validation) after studying for whole year (training). Accuracy and loss are also calculated for validation data. Ideally, accuracy should be increasing, and loss should be decreasing during training and validation processes to construct an efficient model.
The first crucial step before the actual training starts is preparing the dataset. For more details, please refer Data Preprocessing, Datasets and Data Loaders page.
Training and Validation Dataset
The training and validation datasets are subsets of the main dataset, generated by dividing the main dataset according to a user-defined ratio, such as 80/20 or 70/30 etc. The training dataset is employed to train the model, allowing it to learn patterns and relationships. On the other hand, the validation dataset is reserved for evaluating the model’s generalization performance. This division ensures that the validation data remains distinct from the training data, remaining unseen by the model and serving as an authentic measure of validation.
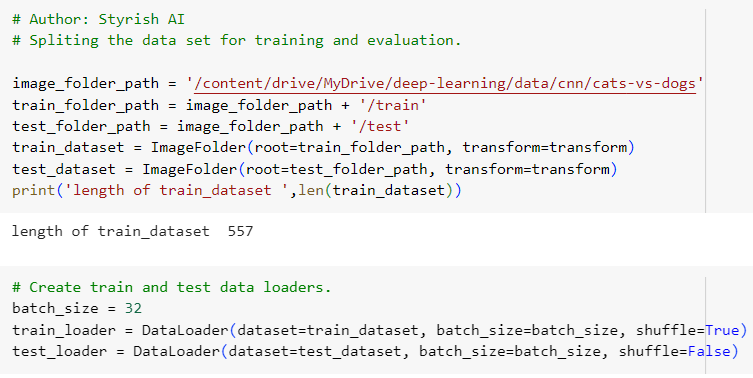
Below is the code for training and evaluation data split in PyTorch.
Defining a Model
Based on our need, we need to create a model class and initiate it, which we will be training and validating. Model is our end product which can be trained using various hyperparameters and can be used for the task on which it has been trained upon. For example, a Convolutional Neural Network (CNN) model can be used for image classification, object detection etc. Recurrent Neural Network (RNN) models are designed for sequential data processing, making them well-suited for tasks where the order of the input elements matters. This includes natural language processing (NLP), time-series prediction, speech recognition, and more. Transformer is another type of model, which is widely used application for NLP tasks, such as machine translation, question-answering, sentiment analysis and many more. Before utilizing these models for their intended tasks, it is essential to train them extensively using a substantial amount of data.
Below is the example of CNN model class in PyTorch. Since this is a CNN model, it comprises layers specific to CNN model, such as Conv2D, MaxPool2D etc. You have to create a class extending PyTorch nn.Module and overriding __init__ and forward functions.

Understanding Training Loop
In PyTorch, the training loop is the iterative process of training a neural network model on a dataset. Each iteration is called Epoch. It involves forward and backward passes, optimization, and updating the model parameters.
Forward pass refers to the process of moving input data through the network’s layers to obtain the final output or prediction. This process involves a series of calculations based on the model’s parameters (weights and biases) and activation functions. Forward pass is implemented by overriding forward() method in model as shown in screenshot above. The return of the forward() function represents the model’s prediction for the given input. Loss is computed based on the difference between the predictions and the actual targets or ground truth. This step involves applying the loss function (e.g., Mean Squared Error, CrossEntropyLoss, Binary Cross-Entropy Loss or BCLoss etc.). For more details on loss functions, please refer page Optimizers and Loss functions.
Backward pass, also known as backpropagation, is a key step in training neural networks. It is the process of computing the gradients of the model’s parameters with respect to the loss. These gradients are computed using the chain rule of calculus by propagating the error backward through the network, indicating how much the loss would increase or decrease if the parameter values were adjusted. loss.backward() method is used to initiate the backward pass.
Once the gradients are computed, an optimization algorithm (e.g., gradient descent, stochastic gradient descent etc.) is used to update the model’s parameters. The optimizer adjusts the parameters in the direction that reduces the loss. For more information on optimizers, please refer Optimizers and Loss functions. step() function on optimizer is called to update the weights for the next run. To calculate the fresh gradients for each epoch, those are also set to zero as the first step of the loop.
Below is the example of training loop in PyTorch, explaining each step-in associated comment.

Validation of Model
Validation involves assessing the performance of the model on a separate dataset that was not used during the training process. The purpose of validation is to estimate how well the model generalizes to new, unseen data. A portion of the dataset, distinct from the one used for training, is set aside for validation. This dataset is not seen by the model during training and serves as an independent evaluation set. The model’s predictions are compared to the true labels in the validation set, hence accuracy is calculated. Validation performance can be used for early stopping, a technique to prevent overfitting.
Overfitting is a common problem in machine learning where a model learns the training data too well, including its noise and outliers, to the extent that it negatively impacts its performance on new, unseen data. In other words, an overfit model captures the training data’s details and patterns to the point of fitting the noise or random fluctuations in the data rather than the underlying true patterns.
Below is the screenshot for validation code in PyTorch, explaining each step-in associated comment.

Validation results are often used for hyperparameter tuning. Hyperparameters are parameters that are not learned during training, such as learning rate. The validation set helps select the best combination of hyperparameters for optimal model performance. Learning rate should be determined efficiently, as higher the learning rate may jump the local minimum in gradient descent curve, resulting to miss the point where the loss could be minimum. An extremely low learning rate leads to small updates in the model parameters during each iteration. As a result, the optimization process takes longer to reach the optimal or near-optimal solution. More details about gradient descent in Optimizers and Loss functions.
Once satisfactory results have been achieved during validation, the model can be saved to your preferred location, making it readily available for its intended use.