Data preprocessing is a crucial step in the field of artificial intelligence (AI) and machine learning (ML)/ deep learning (DL). It involves the transformation of raw data into a format that is suitable for training and testing machine learning models. The goal of data preprocessing is to improve the quality and effectiveness of the data, making it easier for models to learn patterns and make accurate predictions. Data Preprocessing may be applied in various types of models before training it on a specific dataset. For CNN, data preprocessing may lead to resize, normalization, augmentation etc of image dataset, while on the other hand, for NLPs, that may be related to tokenizing, embedding etc. of data. Data preprocessing is required as a first step before the model is trained and validated. Let’s understand data preprocessing in detail.
Data Preprocessing in CNN
CNN models mostly deal with computer vision related tasks, such as image recognition, classification, object detection, segmentation etc. Consider an example of CNN handling with multiple images. Before we train the model, we need to make sure that images are all in proper sizes, formatted, normalized etc., so that the images can be fed into the network. One of the important operations in data preprocessing in CNNs is Image augmentation. Image augmentations makes sure the same images are available from different angles like horizontal flip, vertical flip etc. to increase the volume of data which facilitates in training the model.
Normalization
Normalization means normalizing the pixel values to standard scale ranges from [0, 1] or [-1, 1]. This helps CNN to converge faster. The goal of normalization is to bring the data into a comparable range, making it easier to compare and analyze different features. Normalized value of a pixel is calculated using below formula.
- X is the original data point or pixel value.
- μ is the mean of the dataset.
- σ is the standard deviation of the dataset.
For each feature (column) in your dataset, calculate the mean of the values. The mean is calculated by summing up all the values and dividing by the total number of values.
The standard deviation measures the amount of variation of a set of values using below formula.
Below are the examples of calculating normalized values for some sample pixels in PyTorch. First screenshot is doing normalization after calculating standard deviation and mean using mean() and std() functions, and second screenshot calculates those using transform function of PyTorch, which uses the same formula in itself.
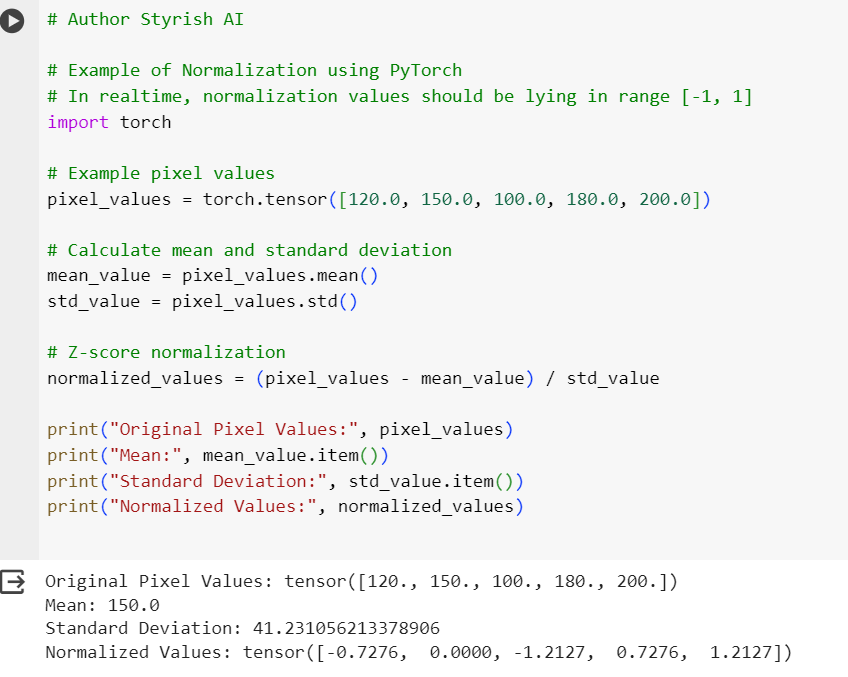
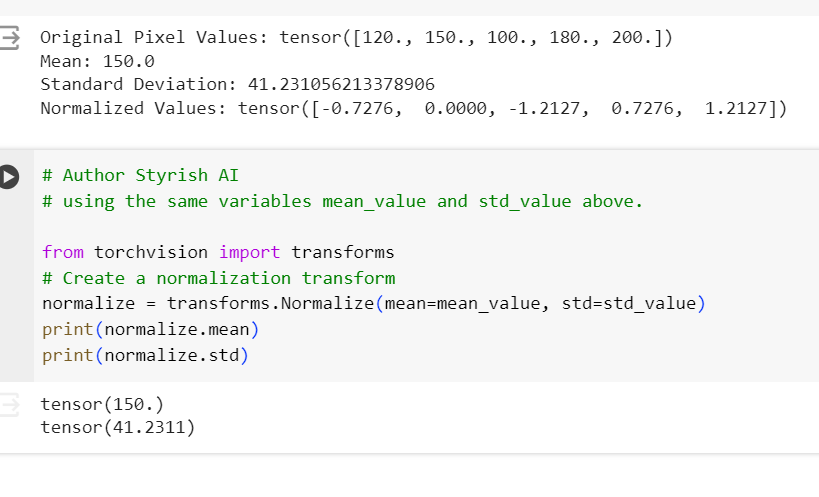
Image Augmentation
Image Augmentation is another important concept in data preprocessing for CNNs. As discussed above, Image Augmentation is used to increase the volume of dataset by generating new images from existing ones by rotating them at different angles, vertically or horizontally flipping, increasing contrasting or brightness of images etc. Image Augmentation helps model to be more robust by providing more diverse data for its training and validation.
Below screenshot refers the Image augmentation using PyTorch and PIL and visualize the difference.


If you see above, a variant from original image got generated which can also be used in training along with original image.
Apart from the above two, there are other operations also available regarding data-preprocessing in CNN like grayscale conversion, which is used for converting RGB images to grayscale images that is helpful to reduce input dimensionality and increasing computational efficiency.
Data Preprocessing in NLPs
Data preprocessing is a crucial part in Natural language processing tasks also. Models which are dealing NLP tasks such as transformers, RNNs preprocess the data to make it suitable for model to train on. Preprocessing of data in NLPs include different steps as the data is mostly in text format unlike CNNs.
Tokenization
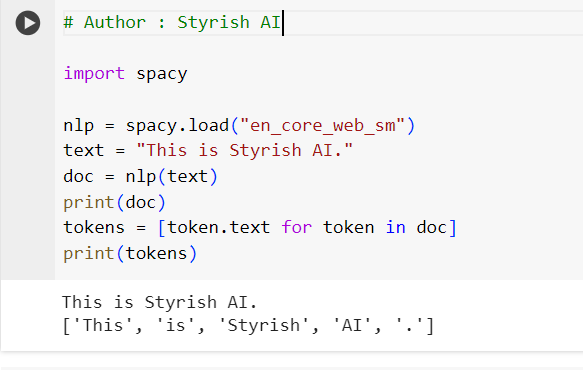
Tokenization is the process of breaking down text into smaller units, called tokens. In the context of Natural Language Processing (NLP), tokens are usually words or sub words. Tokenization is a fundamental step in preparing text data for machine learning models. There are different approaches to tokenization, depending on the specific requirements of the task, but we would focus one of the most prominent and powerful tokenizers named ‘spacy‘. In transformers, there are bunch of useful tokenizers have been provided by Hugging face libraries, such as BertTokenizer etc.
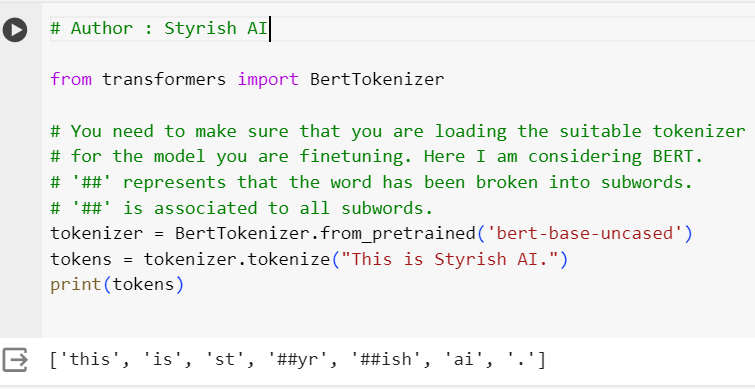
Stopwords Removal
Stopwords (common words like “the,” “and,” “is”) are often removed from the tokenized data as they may not contribute significantly to the meaning of the text.
Building Vocab
Vocab or Vocabulary is an object which holds the Unique words from text and maps it with its frequency. When using pre-trained word embeddings, the frequency information can be used to initialize the embeddings. More frequent words may receive more informative embeddings during initialization, potentially enhancing the model’s performance.
Below is the example of building Vocab in PyTorch.


Representing text as numbers
After the vocab is built, the next step should be representing text as numbers. Models cannot understand texts, so all the tokens should be converted to its corresponding number.
There are multiple strategies you might consider to convert the text into numbers or converting the text to vectors before feeding it to the model. Let’s understand those.
First one you might think about “One-hot encodings“, where you can hot code each word in your vocabulary. For example, consider a sentence “This is the page from Styrish AI.” When you are building up the vocab for the tokens in this sentence, it might end up with ‘This’, ‘is’, ‘the’, ‘page’, ‘from’, ‘Styrish AI’. To represent each word, you would create a vector for each word equal to the vocab length (here vocab length is 5) with all zeros at each index, and one at the index corresponding to the word.
| This | is | the | page | from | Styrish | AI | |
| This | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| is | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| the | 0 | 0 | 1 | 0 | 0 | 0 | 0 |
| page | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| from | 0 | 0 | 0 | 0 | 1 | 0 | 0 |
| Styrish | 0 | 0 | 0 | 0 | 0 | 1 | 0 |
| AI | 0 | 0 | 0 | 0 | 0 | 0 | 1 |
Consider a sequence having thousands of tokens, it will have all 0s and only 1 for single token is vector, hence not really efficient approach.
Another strategy to do it is “Representing text as numbers“, where you can encode each word with a unique number. For the above example, it can be assigned as [1, 2, 3, 4, 5]. This looks ok, but still does not seem to capture relationships between the word as integer encodings are arbitrary.
Word Embeddings
Word embeddings give us a way to use an efficient, dense representation in which similar words have a similar encoding. In other words, word embeddings are numerical representations of words in a continuous vector space, where semantically similar words are mapped to nearby points. These representations capture semantic relationships and contextual information about words, making them useful in various natural language processing (NLP) tasks. Word embeddings are typically dense vectors of fixed dimensions, and they are learned from large amounts of text data using unsupervised learning methods.
These vectors can be initialized randomly or can be loaded from pretrained algorithms such as Glove, Word2Vec etc., and further updated/ adjusted via backpropagation during the training of the model. nn.Embedding module in PyTorch and tf.keras.layers.Embedding module in TensorFlow are used for word embeddings.
In the below screenshot, word embeddings have been initialized via glove, which can be further finetuned based on the dataset while training the model.

Datasets
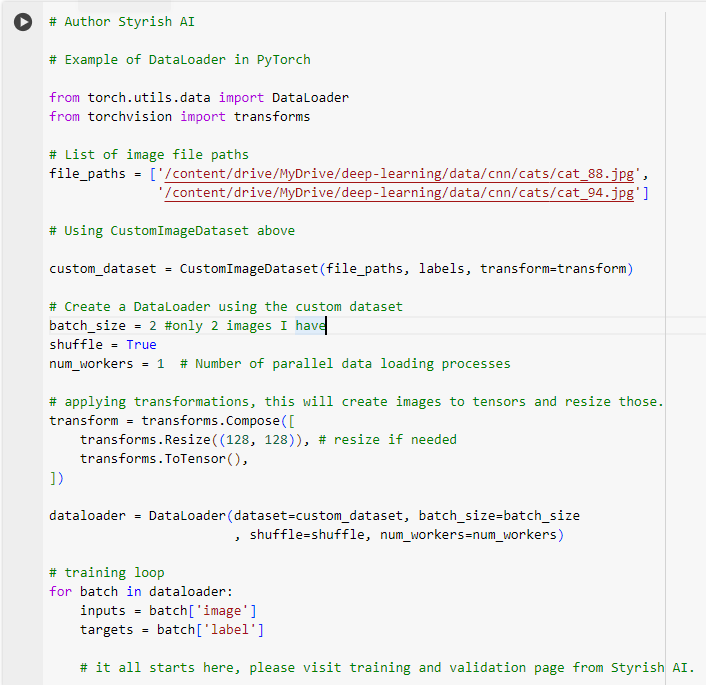
In the context of deep learning and machine learning, a dataset is a collection of data used to train, validate, and test a model. A dataset typically consists of examples or instances, where each example contains input data and corresponding output labels. The primary purpose of a dataset is to provide the required information for a machine learning model to learn patterns and relationships within the data. Here, we have demonstrated the datasets using PyTorch.
In PyTorch, the Dataset class is a part of the torch.utils.data module and provides an interface for custom datasets. It allows you to create a dataset object to organize and manage your data, making it compatible with PyTorch’s data loading utilities, such as Data Loaders (explained below). The Dataset class is an abstract class, you need to inherit that and override __len__ and __getitem__ methods.
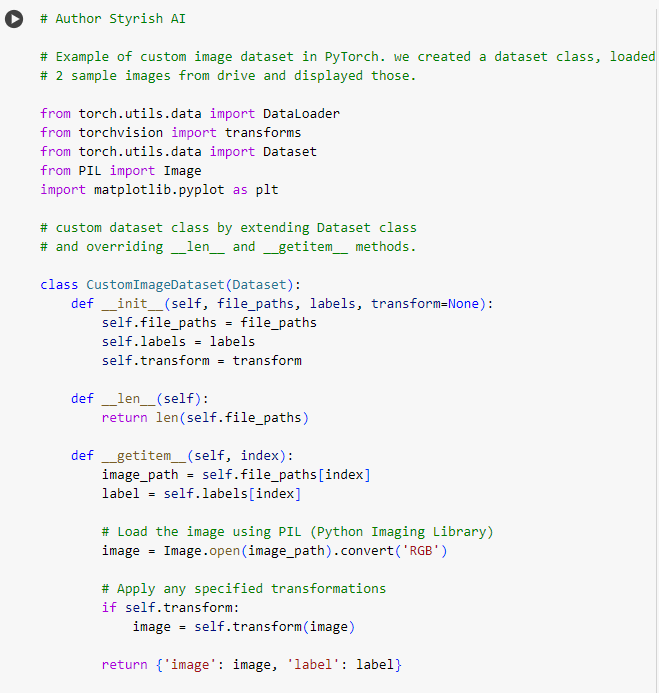
There are number of inbuilt datasets also provided by PyTorch framework for experiment purposes such as MNIST dataset, IMDB movie dataset etc. These datasets are pre refined and can be used for training and validation.
DataLoaders
A data loader is a utility that helps efficiently load and iterate over a dataset during the training or evaluation of a model. Data loaders handle tasks such as batching, shuffling, and parallelizing the loading of data, making it easier to work with large datasets and train models efficiently. Usually the training loop is iterated against the DataLoaders which are prepared from the datasets.
In PyTorch framework, torch.utils.data.DataLoader class provides an implementation of a data loader. It is part of the torch.utils.data module. The DataLoader works in conjunction with a PyTorch dataset, which is an object representing a dataset and provides methods to load individual samples.
DataLoader features include
Batching, Data loaders allow you to specify the batch size, and they automatically create batches of samples for each iteration during training or evaluation.
Shuffling, During the training phase, it’s common to shuffle the data to ensure that the model sees a diverse set of examples in each epoch. Data loaders can shuffle the data before creating batches.
Parallel Loading, Data loaders can load batches of data in parallel, taking advantage of multi-core processors to speed up the training process.